
投稿日
自分の声でのテキスト読み上げ(TTS)を挫折した話
2026年は「Webアプリやサイトを10個作る!」という目標を掲げ、AIとともに開発を続けています。5月は5つ目のアプリの開発に挑戦!派手に挫折!その流れを恥ずかしながら公開しちゃいます。
作ろうとしたもの
Podcastの音声からブログの過去記事を読み上げられるようになるとおもしろそう!と1年くらい前から考えていました。その当時は使い慣れないPythonで挑戦してあえなく挫折。でも今や2026年、AIの進化も凄まじいし、「今度こそいけるのでは!?」と再挑戦することにしました。
今回作ろうとしたのは、私のPodcastの音声から自分の声を抽出(クローン)し、Webクリエイターボックスの過去記事を要約した文章を読み上げ→音声ファイルをダウンロードできるようにする仕組みです。ダウンロードした音声をブログ記事に貼り付けてもいいし、YouTubeショートなんかで流すのもいいな〜ふんふん〜♪ とノリノリで考えてました。
事前準備
音声合成のコアとなるサービスには、クオリティの高さで定評のあるElevenLabsを採用しました。
ElevenLabsとは?
ElevenLabsはAI音声技術を提供するプラットフォームです。数分の音声データをアップロードするだけで、声のクローン(Voice Cloning)を作成できます。テキストを入力するだけで、そのクローン音声に喋らせることが可能です。
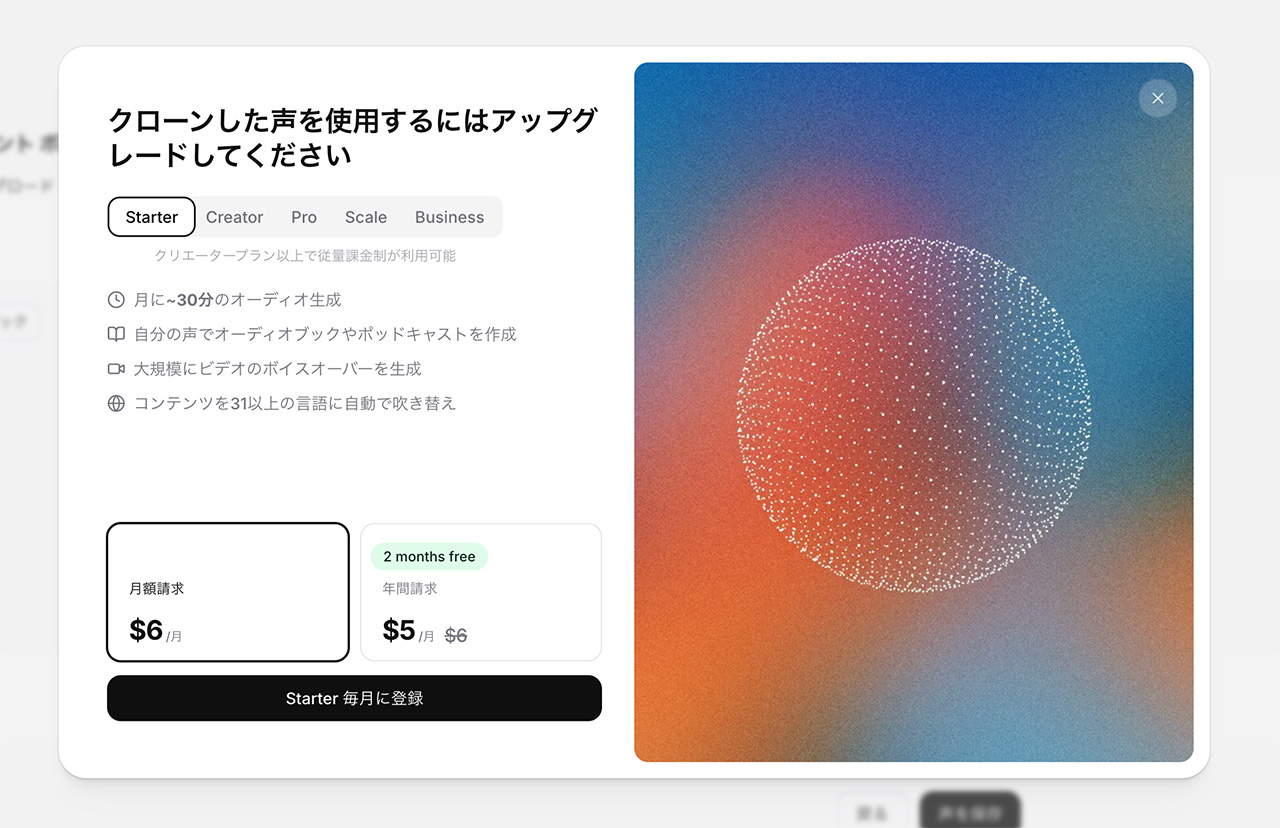
ElevenLabsの無料版だと自分の声(カスタムボイス)は使えないので、今回はStarterプラン($6/月)に登録しました!
APIの疎通確認
まずは、簡単なコードで音声再生ができるかどうかを確認します。この音声生成ページ自体は一般公開するつもりがないので、ローカル環境で動けばOK。シンプルなHTMLファイルを1つだけ作成して試すことにしました。
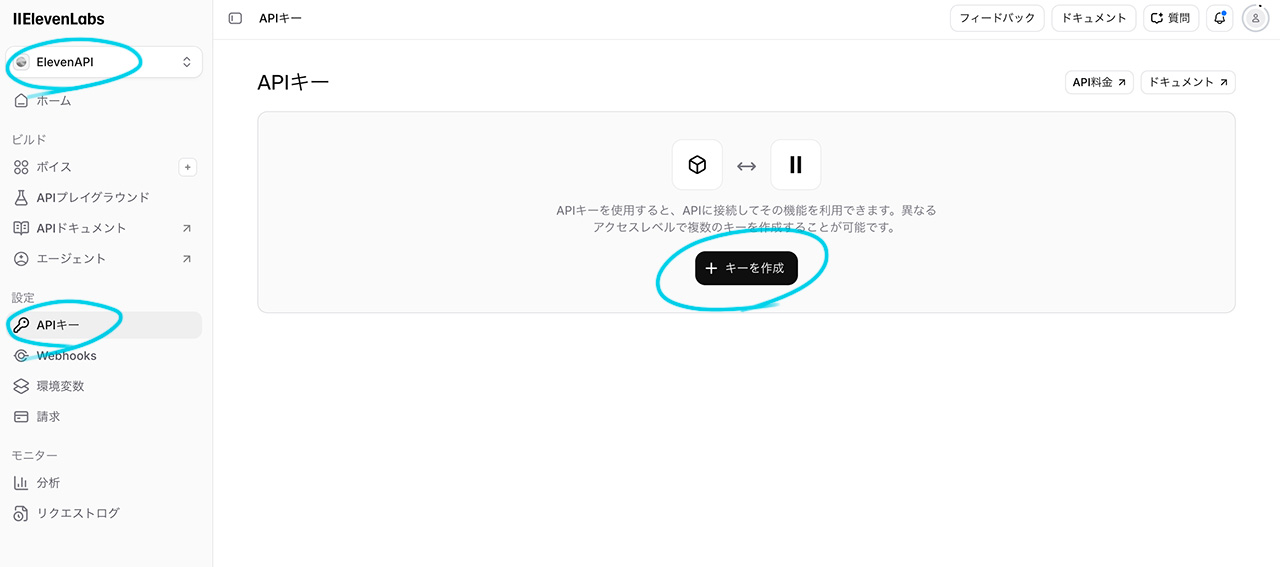
ElevenLabsにログインし、左上の「ElevenAPI」から 設定欄「APIキー」→「キーを作成」ボタンからAPIキーを入手します。
<!DOCTYPE html>
<html lang="ja">
<body>
<textarea id="text" rows="4" cols="50">こんにちは、テストです。</textarea><br>
<button onclick="speak()">再生</button>
<audio id="audio" controls></audio>
<script>
const API_KEY = "ここにAPIキーを貼る";
const VOICE_ID = "ここにボイスIDを貼る"; // 作ったクローンのID
async function speak() {
const text = document.getElementById("text").value;
const res = await fetch(`https://api.elevenlabs.io/v1/text-to-speech/${VOICE_ID}`, {
method: "POST",
headers: {
"xi-api-key": API_KEY,
"Content-Type": "application/json"
},
body: JSON.stringify({ text, model_id: "eleven_multilingual_v2" })
});
const blob = await res.blob();
document.getElementById("audio").src = URL.createObjectURL(blob);
}
</script>
</body>
</html>
コーディング自体はAIのサポートもあり、一瞬で完了!

動かしてみると…
おぉしゃべってる!自分の声だ!すごい!
ただ、いろいろ試した結果、少し漢字の読み方に難ありな印象。これはテキストを送る前にひらがなに変換してあげればマシになりそうです。
ブログ記事のテキスト取得部分を実装
続いて、ブログ記事のURLから内容を抽出して要約する作業です。
WebクリエイターボックスはヘッドレスCMSのmicroCMSを利用しています。microCMSはAPIでコンテンツを取得できるので、スクレイピング不要。記事のスラッグを使って、本文をそのままJSONで受け取れます。
開発環境の構成は以下のように整えました。
- フレームワーク: Next.js(Webクリエイターボックスのリポジトリとは別に新規作成)
- 実行: ローカルで
npm run dev - APIキー管理:
.env.localに書く(.gitignoreでGitHubへのコミットから除外) - バックアップ: GitHubのプライベートリポジトリにプッシュ
.env.local の中身はこんな感じです。
MICROCMS_API_KEY=xxxxxx
MICROCMS_SERVICE_DOMAIN=xxxxxx
ELEVENLABS_API_KEY=xxxxxx
ELEVENLABS_VOICE_ID=xxxxxx
GEMINI_API_KEY=xxxxxx
Gemini APIで要約を組み込む
今回、コーディングアシスタントにはClaude Codeを使っていたので、AIからは当然のようにClaude APIの利用を提案されました。しかし、以前作った別のアプリ「AI Phase Planner」でGemini APIを使っていたので、今回はGeminiに統一することに(あちこちのAIサービスで支払いがバラけるの、管理がめんどいし…)。
.env.local にAPIキー入力して、 npm run dev !でもエラー。あれ、これなんか見覚えあるぞ…。
[GoogleGenerativeAI Error]: Error fetching from <https://generativelanguage.googleapis.com/v1beta/models/gemini-1.5-flash:generateContent:> [404 Not Found] models/gemini-1.5-flash is not found for API version v1beta, or is not supported for generateContent. Call ListModels to see the list of available models and their supported methods.
「あっ、これゼミでやったところだ!」的な感覚で、以前作ったAI Phase Plannerでも同じエラーを踏んでいたので、原因はすぐにピンときました。モデルを gemini-2.5-flash-lite に変更し、無料枠から有料プランへ切り替えることで、無事に記事の要約を出力できるようになりました!
よしよし、ここまでは順調です。
要約した文章を読み上げ
できた!わーい!と思い、ワクワクしながら再生してみると…。
出だしは良さそうに感じましたが、なんだか…日本語非ネイティブのような発音…!?うわーん!自分の声のはずなのに、めっちゃイントネーションが不自然!
どうにかならんもんかと検索してみます。AIに聞いてどうしようもなさそうな時は自力で検索に限ります。
すると、先人の知見「Elevenlabsで感情のこもった自然な日本語ボイスを作る方法をくわしく解説」を発見! どうやら「Eleven v3」という新しいモデルにすると、日本語のクオリティが上がるとのこと。さっそく設定を変更してみます。
もともとのコード(変更前):
body: JSON.stringify({
text,
model_id: "eleven_multilingual_v2",
voice_settings: {
stability: 0.5,
similarity_boost: 0.75,
},
}),
対策後のコード(変更後):
body: JSON.stringify({
text,
modelId: "eleven_v3",
languageCode: "ja",
voice_settings: {
stability: 0.5,
similarity_boost: 0.75,
},
}),
こんな感じで modelID を変更し、言語を ja で日本語を指定。
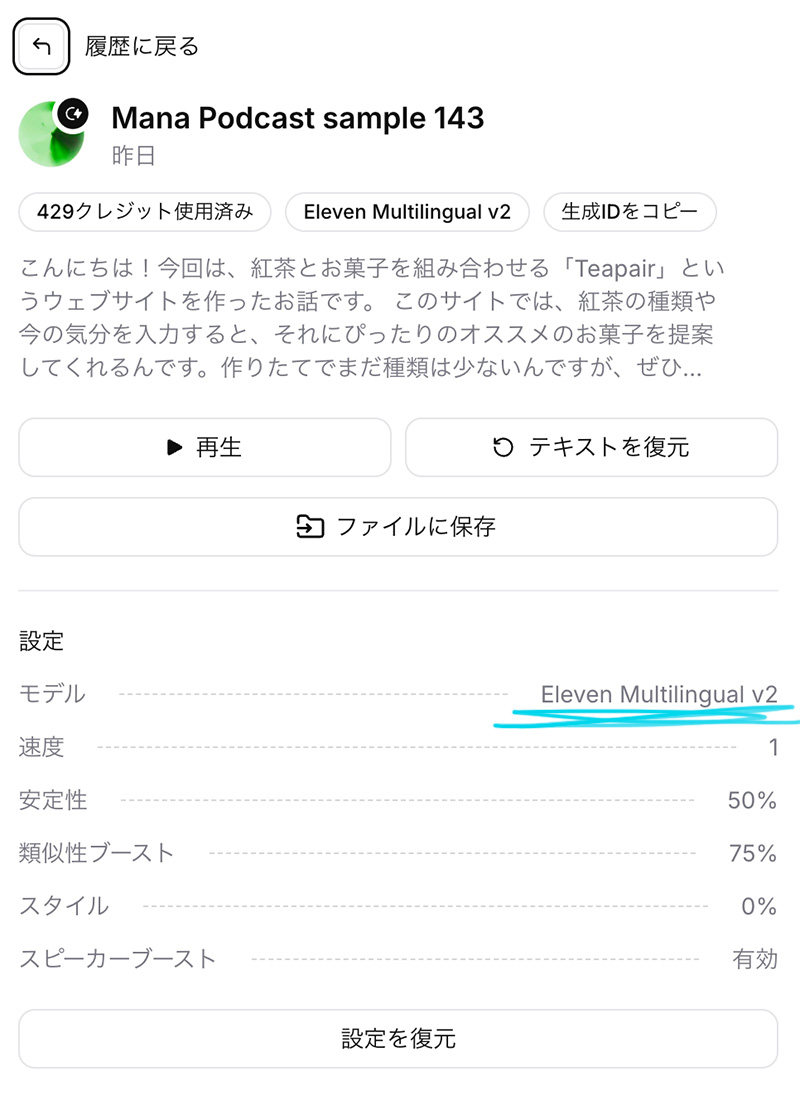
が、どういうわけか eleven_v3 が無視されて Eleven Multilingual v2 にフォールバックしていますね。おそらく私が登録しているStarterプランでは eleven_v3 が使えないのかも?うーん。
ElevenLabsのWebサイト上では V3 で生成できたので、手動で試してみると…
こんちゃ…。いや、まぁマシにはなったんですが。これならずんだもんの方が自然にしゃべってる気がする…。
ずんだもん Ver. がこちら。
というか、もう自分で読み上げて保存した方が早いよね!?という本末転倒な結論が脳裏をよぎり、心がポキッと折れました。
他の選択肢
ElevenLabs以外で、自分の声で読み上げるサービスを探してみました。ただどれも一長一短みたい。
Resemble AI
https://www.resemble.ai/products/text-to-speech
- 日本語対応あり
- Voice Cloning可能
- 有料(ElevenLabsと同程度)
- 日本語品質はElevenLabsと大差ない印象
Microsoft Azure TTS
https://azure.microsoft.com/ja-jp/products/ai-foundry/tools/speech
- 企業向けで品質は高い
- 申請・審査が必要でかなり面倒
- 個人利用には過剰
Coqui TTS
https://github.com/coqui-ai/TTS
- ローカルで動かせる
- Voice Cloningも一応できる
- ただしGPUがないと遅い&日本語品質は厳しい
- 開発も止まっている
ということでこのあたりで諦め。
挫折からの学び
今回の開発で痛感したのは、人間の耳は、身近な人間の声の不自然さにめちゃくちゃ敏感だということです。
初音ミクのようなボーカロイドや、ゆっくり音声(霊夢・魔理沙)、ずんだもんなどは、「ロボット(キャラクター)が喋っている」という前提で聞き慣れているからか、多少のイントネーションの違和感には気づきにくい(むしろそれが味になる)んですよね。その他ナレーションなどができる国産のテキスト読み上げツールも、素晴らしいクオリティを実現しています。
しかし、「自分の声」を再現しようとすると、ベースにあるのがPodcastの自然な会話なだけに、比較対象が脳内にあるせいで少しのズレが「不気味の谷」となってくっきりと浮き彫りになってしまいます。もっと手軽に、自然な日本語の自分の声が作れるようになる未来を待ちましょうかね…。
はいあがろう。「負けたことがある」というのがいつか 大きな財産になる。
(井上雄彦『SLAM DUNK』より)
でも悔しいのでまたいつか挑戦してやるんだから!何かおすすめの方法などあればご教授くださいませ…!5月の開発は残り期間でできそうなものをチマチマ作っているところです。お楽しみに〜。
AIコーディングは万能に見えて、今回のように泥臭いところでつまずくのもまた一興(と、思いたい)。
もし「ドンマイ!」「次のアプリ開発も応援してるよ!」と思ってくださる優しい方がいらっしゃいましたら、以下のリンクからコーヒーを1杯奢っていただけると、泣いて喜びます。次の開発のモチベーションになります!モチベをください!笑